The Gap Between Demo and Production
The standards for a demo are simple: it should be clickable, runnable, demonstrable, and understandable. However, production standards are entirely different: data must not leak, permissions must be strictly controlled, user data must be isolated, secrets must not be exposed on any client, exceptions must not be silently swallowed, issues must be traceable, deleted data must be recoverable, and serious problems discovered post-launch must be reversible.
The difference between these two is not in technical difficulty, but in engineering systems. AI can help you generate a usable login page, but it won’t automatically tell you if your JWT expiration time is set correctly, if the refresh token mechanism is secure, or how to handle session theft and multi-device logins.
AI can assist in generating a customer list, but it won’t automatically check if the database query for this list enforces user isolation. Will User A accidentally read User B’s data? Does the API interface perform permission checks, or does it rely solely on hiding buttons in the frontend?
The irony is that these issues do not affect the demo experience. You open the page, see your data, and everything seems normal—until one day, a user accidentally modifies a URL parameter and discovers they can see all orders across the site—the incident has truly occurred.
Five Common Pitfalls in Development
Why do apps developed with Vibe Coding often encounter issues post-launch? There are five typical pitfalls:
1. Default configurations are often set to “open”. Many cloud services and frameworks have very permissive default settings to reduce the difficulty of getting started. Databases may allow public access by default, storage buckets may be publicly readable, and management backends may lack any authentication. Experienced developers instinctively tighten permissions upon encountering a new service, but those using AI to create apps may be unaware of these settings. They see the page open and data stored, but have no idea how many doors are wide open behind the scenes.
2. Security boundaries are invisible. Hiding a button in the frontend does not equate to backend permission checks. Not displaying certain data on a page does not mean the database prohibits cross-user access. These are muscle memory for engineers but completely foreign to those without a technical background. Tools have lowered the development threshold, but the threshold for risk assessment remains unchanged.
3. AI inherently tends to “get it running first”. When you ask AI to “help me create a user management page,” it will prioritize creating the page, connecting the data, and ensuring interactions work. Security hardening, permission control, exception handling, and logging—these aspects are not included unless specified in your prompt, and AI will not automatically supplement them in the first version. It is friendly to demos but may not be beneficial for production.
4. Vibe Coding does not equal “no knowledge programming”. Many people misunderstand Vibe Coding as being able to write software without any programming knowledge. The reality is that while you can use AI to generate code, debugging, problem localization, assessing solution quality, and identifying security risks still rely on engineering experience. When AI-generated code hides a risk in an area you cannot understand, you may have little ability to detect it.
5. An app is a system, not just a collection of pages. Behind an app, there are at least front-end, back-end, database, caching, file storage, API gateways, identity authentication, and logging systems—it’s a combination of a multi-layer system. AI can help you quickly piece together each layer, but the integration between layers, boundary condition handling, and exception state management fall under the realm of systems engineering, which cannot be covered by a single prompt.
What Can Be Done and What Cannot Be Launched Bare
The purpose of discussing these issues is not to dismiss Vibe Coding. I also use AI-assisted development, which indeed compresses a lot of repetitive work. The key is to differentiate scenarios.
Vibe Coding is very suitable for: quickly creating prototypes for investors, validating whether there is demand for a product idea, developing purely internal tools, personal projects or experimental demos, allowing non-technical team members to express product ideas, and reducing repetitive boilerplate work for programmers.
However, the following scenarios should not allow AI-generated products to go live without scrutiny: systems involving medical data, financial data, or sensitive internal corporate data; scenarios involving user privacy information; applications involving payment processes; systems with permission management and multi-role access control; production databases facing a large number of real users; and any scenario that could result in legal or compliance risks if something goes wrong.
If these are involved, at least an engineering review should be added: security review, permission review, data isolation review, and pre-launch checks. The correct use of Vibe Coding is to accelerate the prototyping phase, not to replace the engineering phase.
The Role of Programmers Will Not Disappear, It Will Just Be More Valuable
Regarding whether Vibe Coding will lead to programmer unemployment, I believe this discussion is misguided. If a programmer’s value is merely writing buttons, adjusting styles, and writing simple CRUD operations, then indeed, their value will decrease. However, the true value of programmers has never been about “being able to write code” but rather “knowing what should not be written that way”.
What data cannot be launched bare, what permissions cannot rely solely on the frontend, what interfaces cannot be exposed externally, what secrets cannot be placed on the client, what logs cannot output private information, what delete operations must be recoverable, and what checks must be conducted before going live—AI will not automatically make these judgments for you. AI can generate code but cannot assume engineering responsibility.
As Vibe Coding becomes more popular, another demand will grow: helping non-programmers review AI-generated apps, assisting entrepreneurs in enhancing security, transforming demos into production systems, helping product managers check permissions and data risks, aiding small companies in establishing pre-launch security checklists, and supplementing testing, monitoring, logging, and rollback mechanisms for AI-generated projects.
The future role of programmers will change; they will not write more code but will serve as engineering gatekeepers for AI outputs. They will transform AI-generated products into maintainable systems, auditable systems, recoverable systems, and systems that protect user data.
The Bottom Line of Launching
Ultimately, the most overlooked aspect of Vibe Coding is a sense of “launch awareness”.
Demo thinking is: as long as it runs, it’s a success. Launch thinking is: after an incident, can it hold up? There is no gray area between these two ways of thinking. A system is either prepared to face the chaotic inputs of the real world or it is not. Just because you used AI-generated code does not mean reality will be more forgiving.
AI has democratized app creation, which is a good thing. However, engineering responsibility has not disappeared; it has merely shifted from “I write code, so I am responsible” to “I use AI-generated code, and I am still responsible for the results post-launch”.
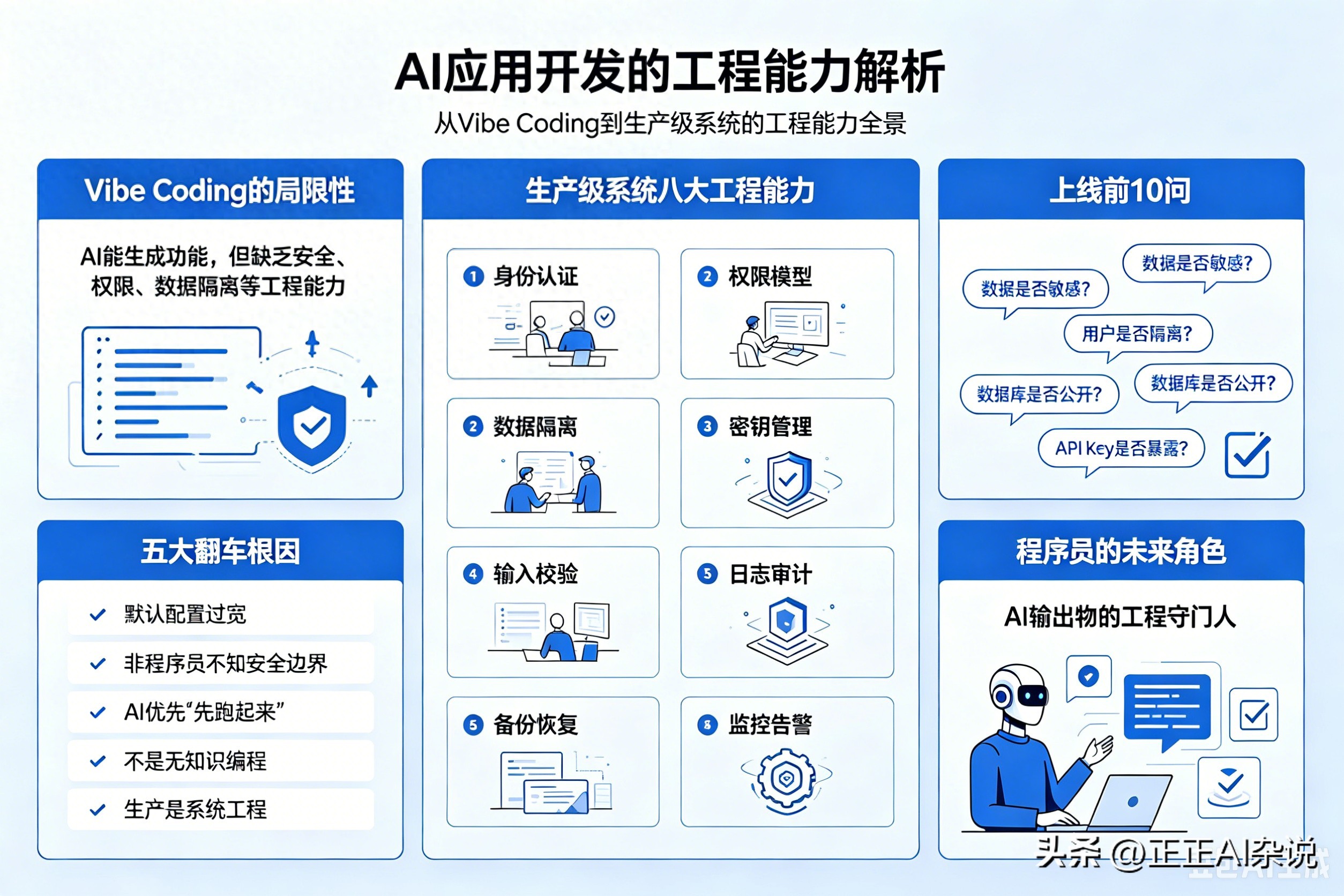
Image Suggestion: AI allows those who cannot write code to also “create apps”, but there is a whole set of engineering capabilities—security permissions, data isolation, secret management, logging, and backup recovery—that AI will not automatically fill in. The correct position of Vibe Coding is to accelerate prototypes, not to skip engineering.
The pitfalls of Vibe Coding do not stem from AI’s inability to produce functionality, but rather from AI generating functionality without addressing engineering boundaries such as security, permissions, and data isolation.
The five root causes of failures: overly permissive default configurations, non-programmers unaware of security boundaries, AI prioritizing “getting it running first”, it is not no-knowledge programming, and production is systems engineering.
Production-level systems require eight engineering capabilities: identity authentication, permission models, data isolation, secret management, input validation, logging, backup recovery, and monitoring alerts.
Ten questions before going live: Is the data sensitive? Are users isolated? Is the database public? Is the management backend authenticated? Is the API key exposed? Programmers’ future roles are not to write more code but to be the engineering gatekeepers of AI outputs.
Vibe Coding makes “getting it done” extremely cheap, but the threshold for “secure launch” remains unchanged. The correct attitude is not to reject it but to use it to improve efficiency in the prototyping phase and introduce engineering reviews before actual launch. The standard for demos is to run, while the standard for production is to ensure it can handle incidents.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.