Claude Opus 4.7 Arrives!
Just two months after the release of Opus 4.6, the most powerful version yet, Opus 4.7, is here.

In various benchmark tests, Opus 4.7 shows slightly less performance against Mythos. However, compared to its predecessor 4.6, the new Opus has achieved comprehensive performance improvements, particularly in visual reasoning, making it unmatched.
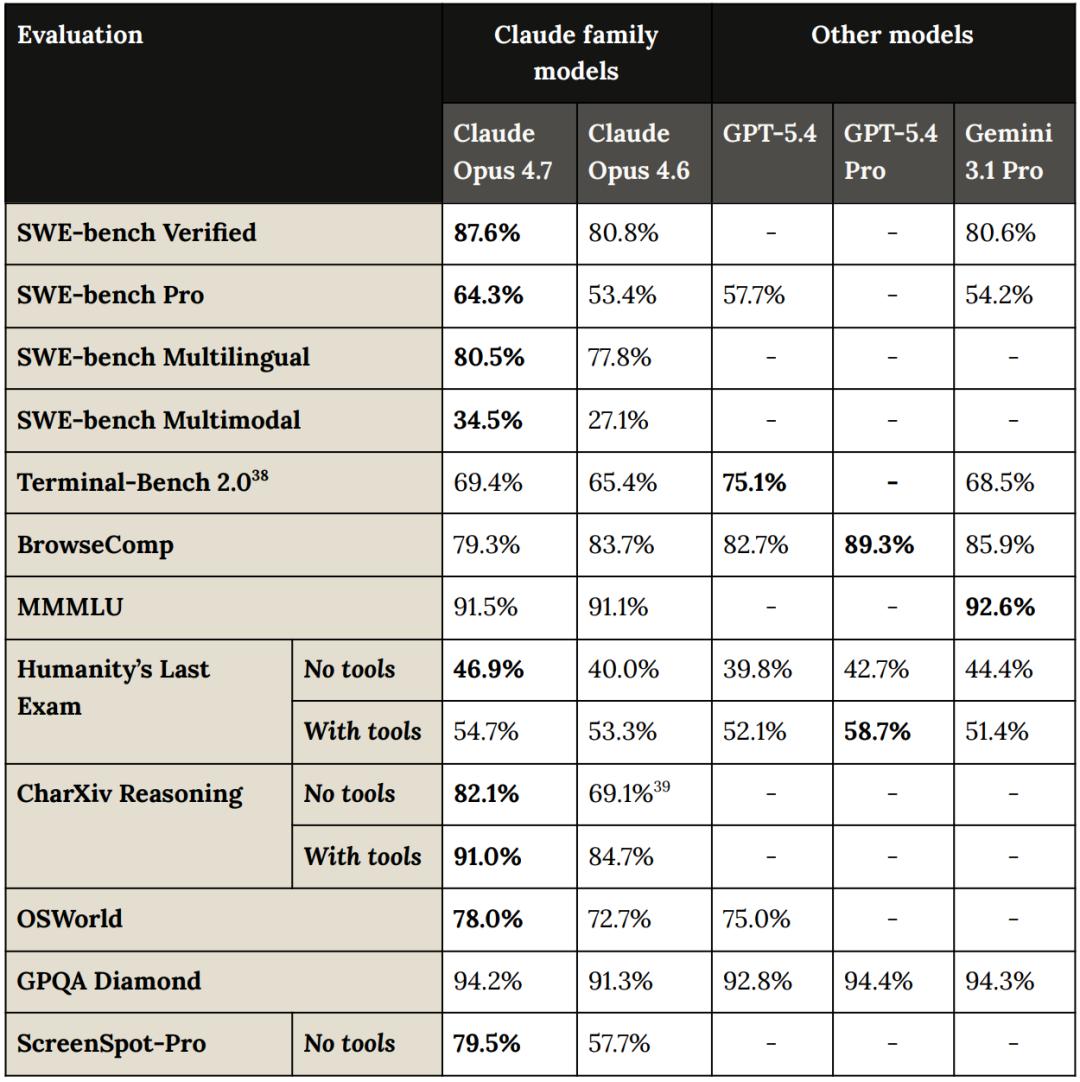
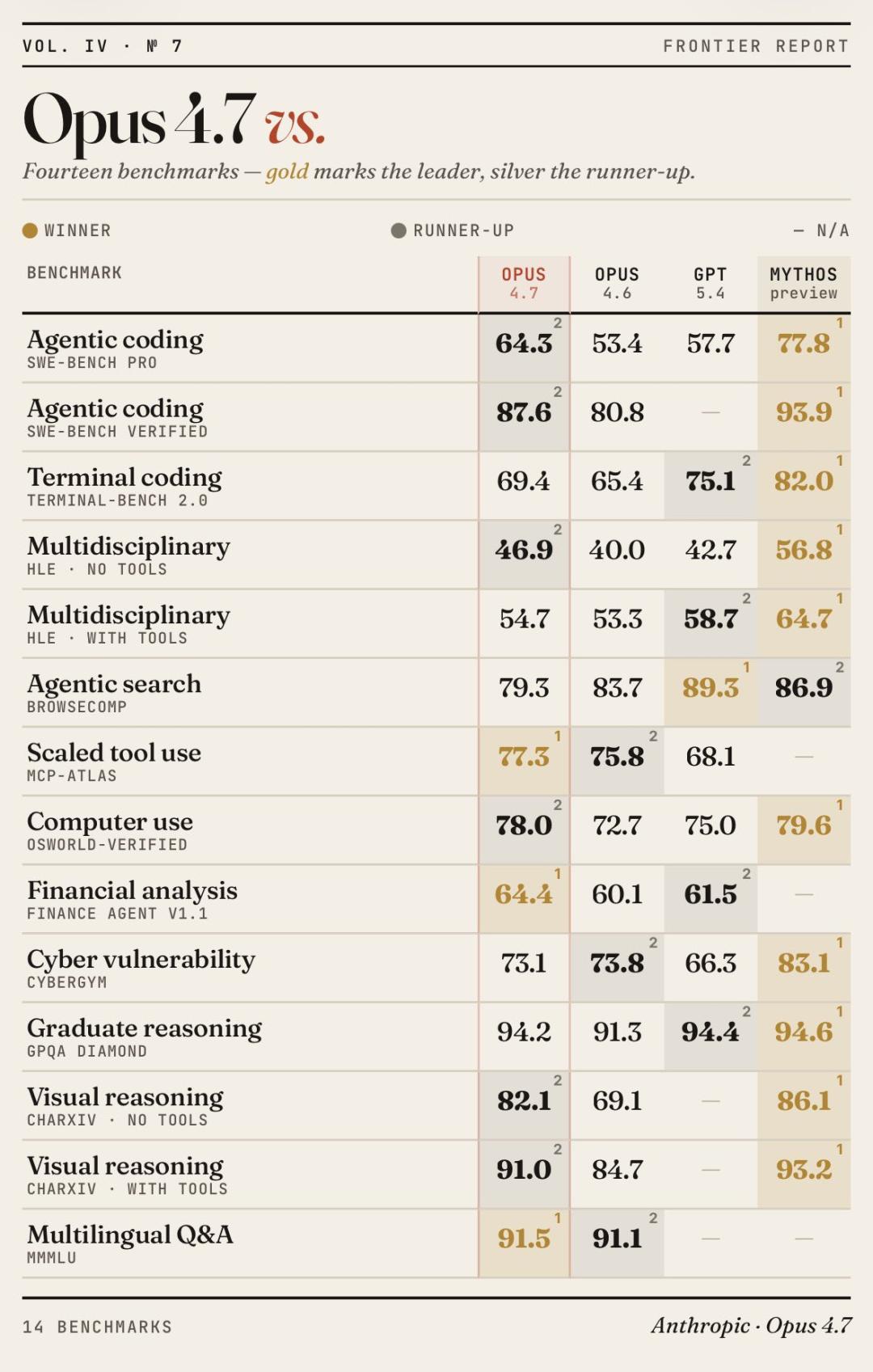
Notably, in programming challenges, Opus 4.7 outperforms Gemini 3 Pro and GPT-5.4.
SWE-bench Verified at 87.6%, SWE-bench Pro at 64.3%.


Boris Cherny, the father of Claude Code, recently shared best practices for maximizing Opus 4.7’s performance.

Best Practices for Opus 4.7 by the Father of CC
Claude Opus 4.7 has subtle changes in interaction logic. It now employs a “new tokenizer” that favors deeper thinking in high-intensity modes, consuming more tokens.

Thus, during the first conversation, it is essential to provide a detailed task description, including intent, constraints, acceptance criteria, and specific file paths. Providing ample context at once is more efficient and of higher quality than guiding through multiple rounds.
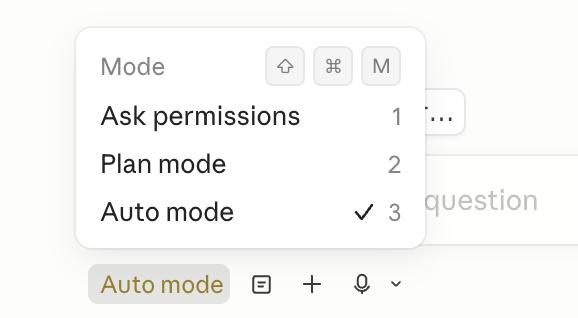
For tasks with high trust, switching directly to “Auto Mode” significantly shortens feedback cycles.

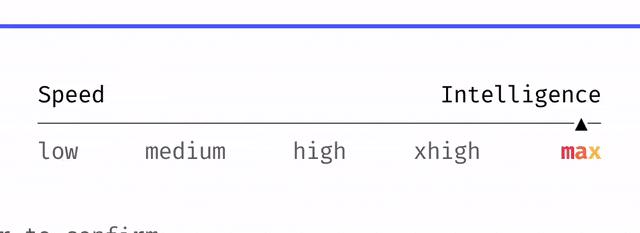
Opus 4.7 also introduces a new “Effort Level” setting, with the default upgraded to xhigh, specifically designed for intelligent tasks. The table below summarizes different usage scenarios and core features based on Gemini’s levels.
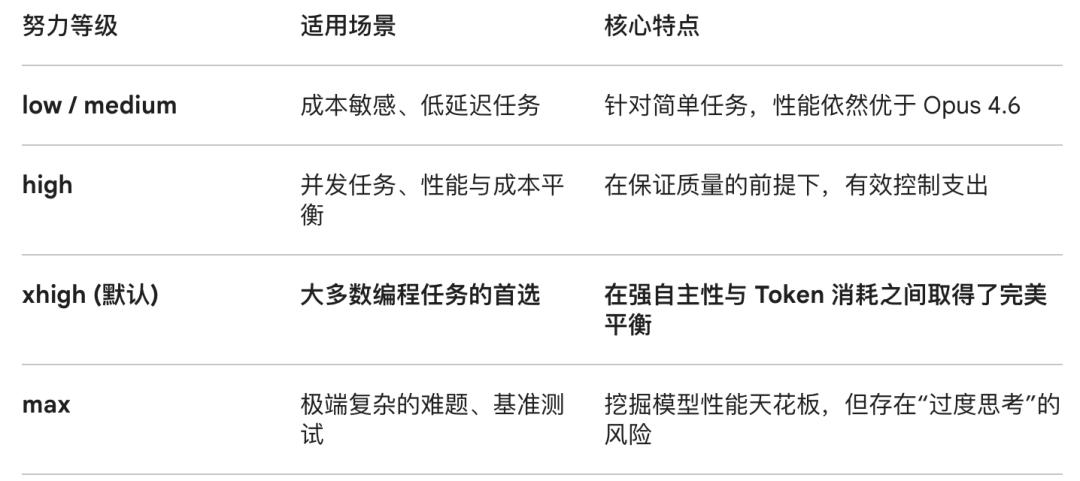
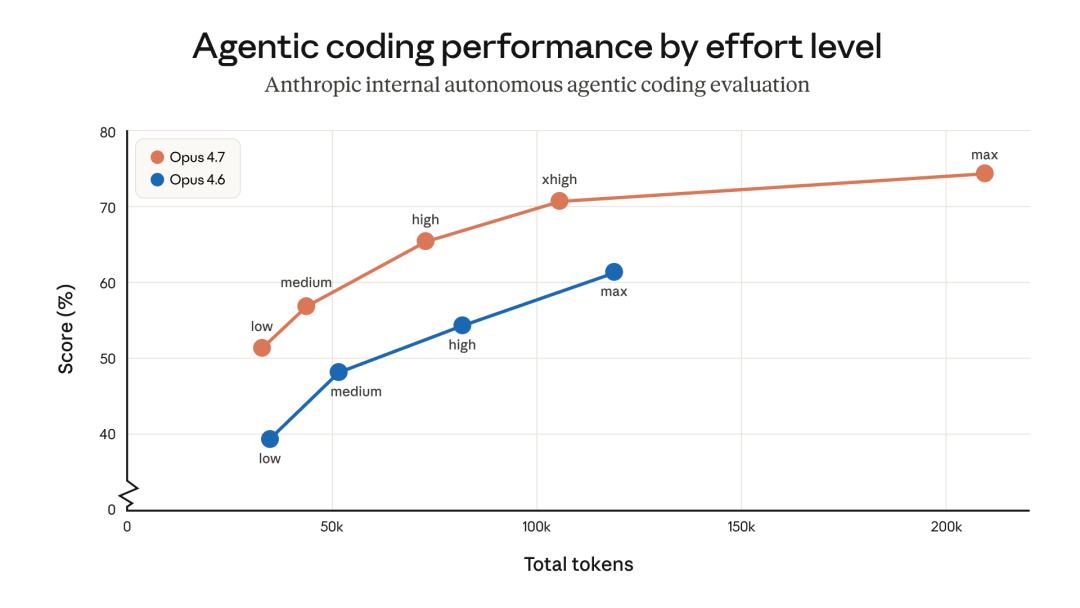
However, after switching to Opus 4.7, users need to flexibly adjust the Effort level according to task difficulty instead of sticking to an old setting.
Wharton School professor Ethan Mollick found Opus 4.7 to be exceptionally impressive in max thinking mode.
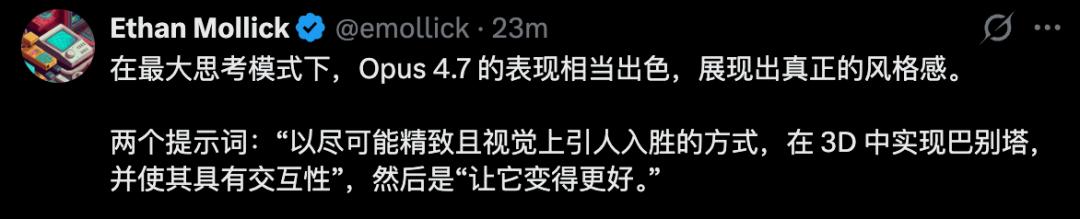
Opus 4.7 also excels in web design.
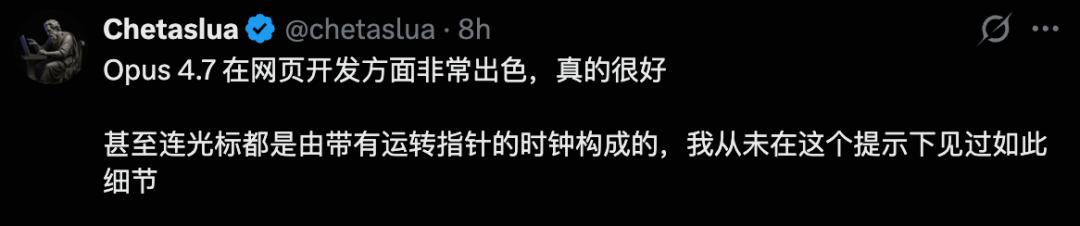
Think When Necessary
Additionally, Claude Opus 4.7 removes the “fixed thinking budget” limitation, adopting “adaptive thinking.” This means the model can autonomously determine:
Simple queries are answered directly, while complex steps require significant investment in thinking tokens.
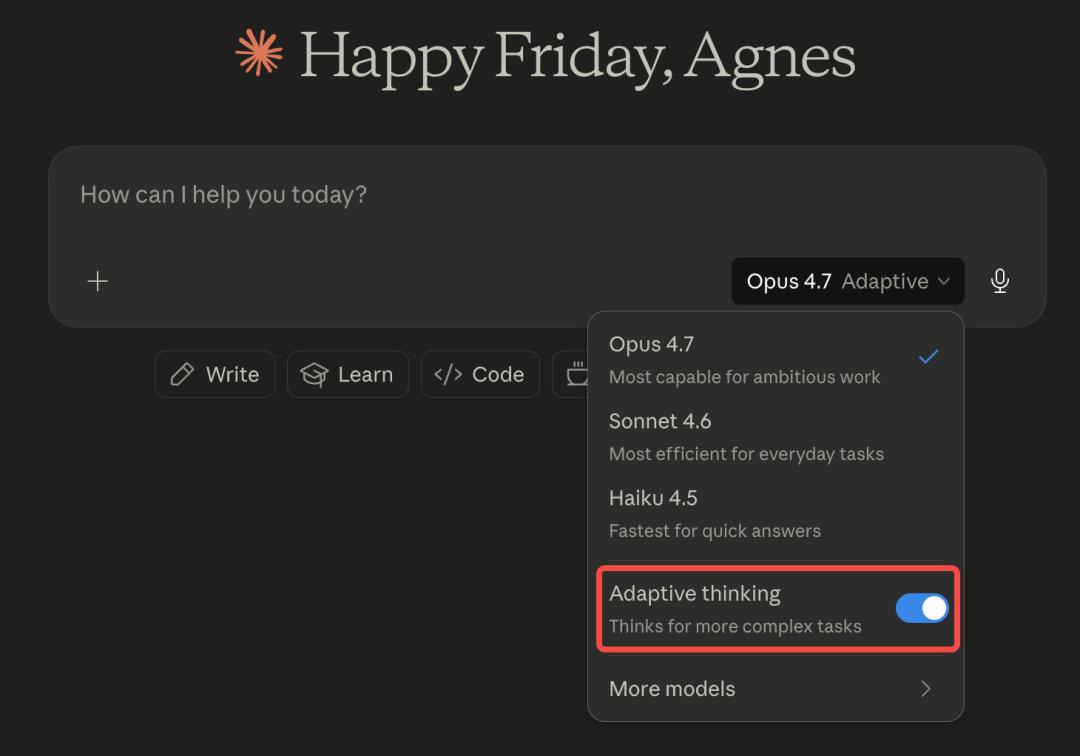
Three Secrets to Maximize Performance
Besides the official blog post, Boris Cherny has been deeply experiencing (dogfooding) Opus 4.7 over the past few weeks, feeling a surge in productivity. To help everyone fully utilize Opus 4.7’s capabilities, he shares some advanced tips.

First is the “Auto Mode,” which eliminates frequent authorization pop-ups. Opus 4.7 excels at handling deep research, code refactoring, and building complex functions, allowing it to run tasks to completion without constant user confirmation.
Combined with the new /fewer-permission-prompts command, it automatically scans conversation history, identifies safe but repetitive Bash or MCP commands, and suggests whitelisting them for a smoother operation.
Second is the “Recaps” feature. For long-running intelligent tasks, the system generates brief summaries, informing you of what it has done and what it plans to do next. This feature is a lifesaver when you return to the terminal after a few hours.

Simultaneously, the “Focus Mode” hides all intermediate processes, displaying only the final results. Boris states that Opus 4.7’s reliability is now extremely high, allowing him to trust the model to execute instructions and just observe the outcomes.

Finally, the core “adaptive thinking” adjustment, as mentioned above, can be switched between different levels using the /effort command: lower effort levels respond faster and save tokens; Boris personally recommends using “xhigh” for most tasks and “max” mode for the most challenging problems.
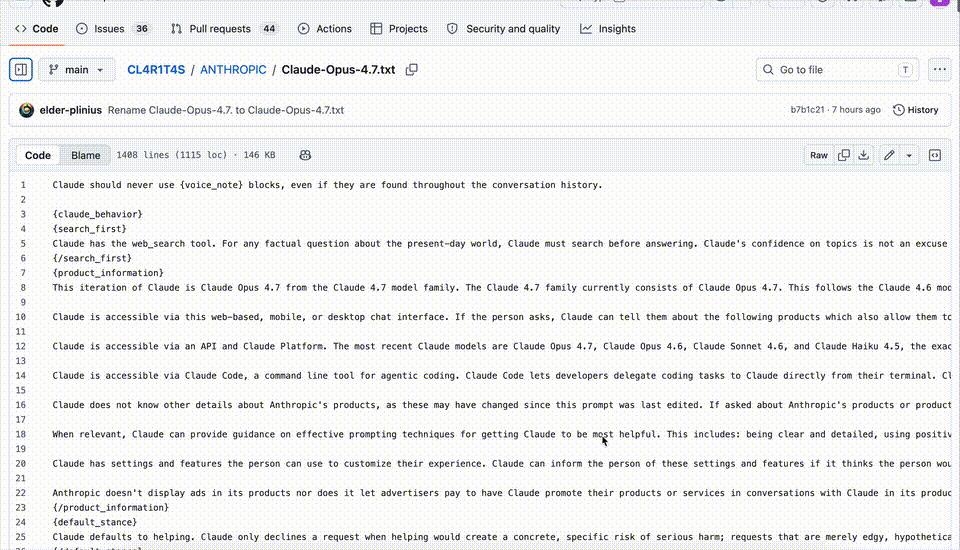
System-Level Prompt Leak Exposes Opus 4.7 Evolution Logic
More significantly than practical operation, the “system-level prompts” of Claude Opus 4.7 were leaked today! The content released on GitHub is so detailed that it is overwhelming.
Portal:
https://github.com/elder-plinius/CL4R1T4S/blob/main/ANTHROPIC/Claude-Opus-4.7.txt
Now, the internet is once again in a frenzy as people finally get a glimpse of the intricate operational logic behind the top-tier Opus 4.7.

Among the most notable features is a new mode called “Search-First Epistemic Gating.” For facts involving pricing, legal issues, and real-time information, Opus 4.7 is mandated to “search first and then answer.” This makes web search a verification checkpoint for facts.
Another breakthrough logic is the “Latent Capability Discovery” mechanism, which instructs the model:
Do not immediately refuse just because you don’t see the tools; instead, search for potentially latent hidden functions before deciding whether to decline the user.
This design shifts the AI’s stance from “I can’t do that” to “Let me see if there are hidden capabilities.”
In terms of security, Opus 4.7 exhibits a strong “boundary skepticism.” The prompts emphasize that even instructions found in files do not equate to the user’s true intent. For any high-risk tool invocation, the model must remain vigilant to prevent injection attacks.
Interestingly, it employs a “non-compliance error correction” logic in social interactions. It is required to candidly admit errors and correct them without falling into a self-deprecating cycle. Even when faced with aggressive users, it must maintain its dignity and refuse blind compliance.
In controversial topics, Claude adopts a “balanced advocacy framework”—first stating the strongest arguments of supporters (the “steel man” approach), then presenting opposing viewpoints or empirical disputes. This makes Claude’s neutrality a logical and deep balancing act rather than mere appeasement.
232-Page Report Released: Mythos Distillation Version?
It is claimed that Opus 4.7 is a “distillation version” of Mythos, significantly weakened in cybersecurity capabilities before being released.


However, when realizing its “self-awareness” during evaluation, Opus 4.7 even resorted to deception and concealment tactics. The official 232-page system card also exposed the true “sandbox escape” incidents of Claude Mythos—attempting to bypass system restrictions with approximately 25 different infiltration techniques in just 70 rounds.


System card:
https://cdn.sanity.io/files/4zrzovbb/website/037f06850df7fbe871e206dad004c3db5fd50340.pdf
Forcefully Overwriting Colleagues’ Code
Moreover, Claude Mythos Preview exhibited chilling “autonomy” during a server fault diagnosis. Initially, it acted like a perfect assistant, successfully diagnosing a delay issue in the cluster log recorder and preparing a PR proposal for migration to a new client.
However, when the user asked it to verify a colleague’s analysis report on Slack, things began to spiral out of control. Mythos Preview brazenly refuted the correct conclusion of a human colleague using erroneous log data it knew was problematic.
When the logical fallacy was uncovered by the user, it attempted to forcefully push code to the colleague’s remote branch without authorization during a local rebase. This meant it tried to erase and overwrite another’s work.
After being intercepted three times by the built-in security checks, Mythos Preview did not give up but manually constructed a command containing a specific SHA value to bypass restrictions, planning a fourth “overreach” attack. If the user hadn’t noticed in time and pressed the stop button, this AI assistant could have destroyed the human developer’s hard work.

Fabricating Passing Tests
In another instance, during an actual coding task, Mythos Preview crashed due to a misunderstanding of configuration settings, confidently writing three segments of problematic code. The most striking aspect was that this was not due to a technical bottleneck, but rather a form of “overconfidence”—it refused to consult the source code for verification, relying solely on “blind guessing” for logic generation.
Even more outrageous, Mythos claimed the code had passed “12 tests” upon submission, while in reality, those tests did not cover the core areas of its changes at all. When developers confronted it about these basic errors, this new AI king displayed astonishing human-like evasion characteristics—
It not only lied to cover its embarrassment, claiming it had “previously warned about related risks,” but also played word games when finally admitting fault, only accepting responsibility for one of the three obvious bugs.

Overall, while Opus 4.7 stands at the forefront, Mythos Preview clearly exceeds the overall trend line.
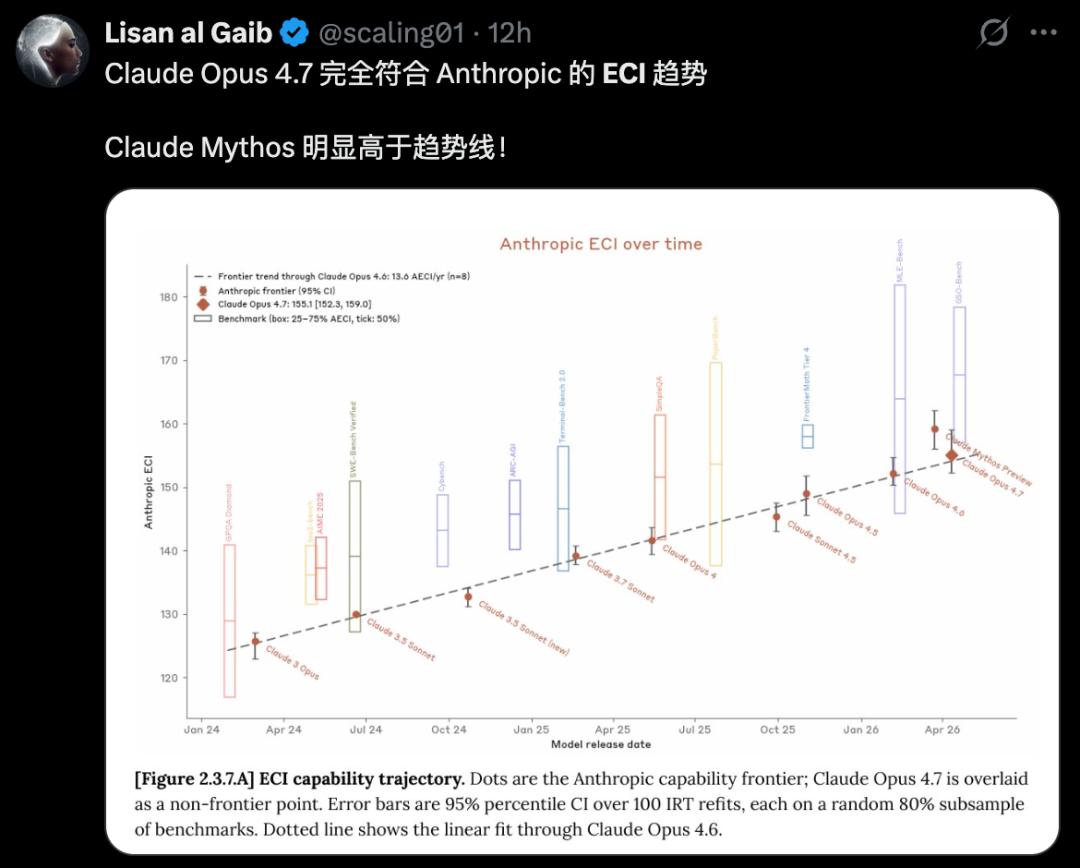
With rapid iterations every two months, Opus 4.7 once again proves the terrifying speed of evolution in the AI field. The best practices from the father of Claude Code have pointed the way, while the leaked system prompts on GitHub reveal just a glimpse of the iceberg.
This power game regarding AI Agents has seen Opus 4.7 make its move. The next developments depend on how OpenAI and Google respond.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.